There is a particular kind of technical debt that looks like progress until the day it doesn’t.
A mid-sized company had built a data platform entirely on Airflow. A dozen pipelines pulling from external APIs, processing the results, joining against a Postgres database, pushing outputs downstream. The team had no prior Airflow experience. What they had was Claude Code, a mandate to move fast, and a company culture that measured engineering output by how aggressively AI tooling was used.
The result was applauded internally. Pipelines were shipping in days. The dashboard showed green. Nobody asked what was inside.
What they built
Each pipeline lived in its own Docker project. Separate repository, separate folder structure, separate docker-compose.yml. Twelve pipelines meant twelve environments, each slightly different from the last, each reflecting whatever conventions made sense to whoever generated it that week.
Inside each project, the DAGs were dense. PythonOperators calling .py files that called other .py files, chains of imports, business logic, API pagination, response parsing, joins against Postgres. All of it living inside Airflow tasks. The DAG wasn’t describing an orchestration flow. It was the application.
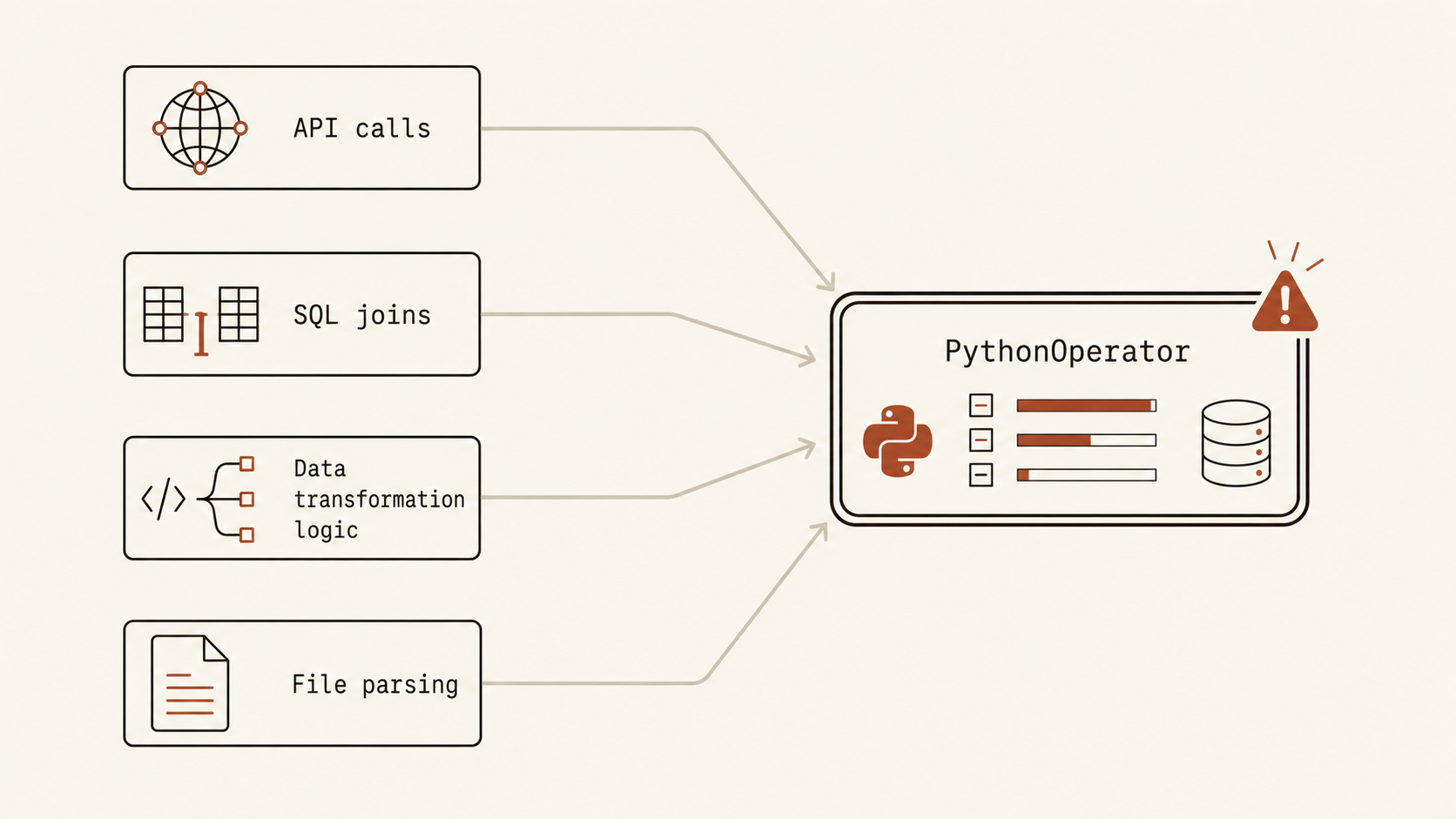
This is the core misuse. Airflow is an orchestrator. Its job is to answer two questions: what runs, and when. The scheduler, the workers, the webserver are designed to manage task state and execution order, not to execute data processing workloads. When you put real logic inside operators, you are running that logic inside Airflow’s own processes. The workers saturate. The scheduler slows down. Memory climbs. Tasks that should be lightweight coordination calls become the thing that brings the entire platform down under load.
The team didn’t know this because the tool that built it didn’t tell them, and nobody reviewed what was being generated.
The moment it broke
The engineer who built most of it left. This is always when systems like this reveal themselves.
Nobody else could start the environments. The Docker projects had hardcoded connection strings and API credentials in .env files that existed on one laptop. Some projects referenced internal hostnames that pointed to nothing on any other machine. Dependency pinning was inconsistent across projects: same library, three different versions, one patched by hand in a way nobody documented.
Two weeks of effort from two engineers produced one pipeline running in a staging environment. The other eleven were dark. The company had a data platform that worked as long as the person who built it was in the room.
At the same time, leadership had decided to migrate to the cloud. Both problems arrived together: a platform nobody could operate, and a mandate to move everything to Azure.
What we did
We didn’t try to rescue the existing setup. There was nothing worth preserving architecturally. The logic was real but it was buried inside layers of generated code that nobody fully understood, and untangling it would have taken longer than rewriting it with clear intent.
The migration became the rewrite.
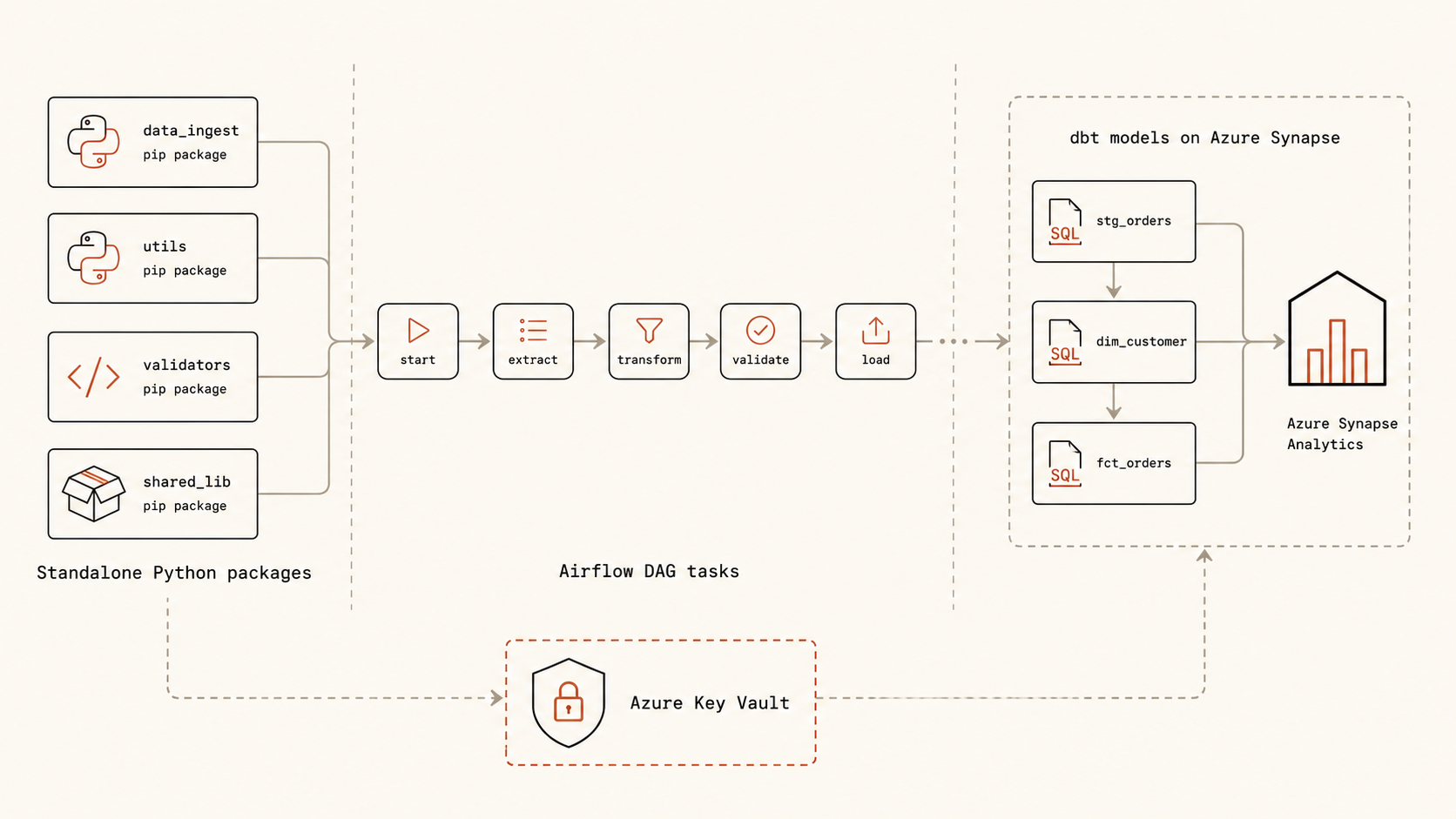
We consolidated the twelve Docker environments into a single Azure-hosted Airflow deployment. One environment, one requirements.txt, one secrets backend wired to Azure Key Vault. Every credential that had been living in a .env file on someone’s laptop moved into the vault on day one.
The API integrations were rewritten as standalone Python packages. Tested independently, versioned, deployable without Airflow in the picture at all. The DAGs became thin: instantiate a client, call a method, move to the next task. No logic inside the operators. If a task failed, you could reproduce the failure outside of Airflow entirely.
Transformations moved to dbt on Azure Synapse. The Postgres joins that had been happening inside PythonOperators became dbt models with lineage, tests, and documentation. For the first time, someone could open the project and understand what the data was doing and why.
What this cost
Three months. The first month was mostly archaeology: reading generated code, inferring intent, mapping what each pipeline was actually supposed to do versus what it was doing.
The company’s culture of AI-first development wasn’t wrong in principle. The problem was that AI-generated code was being treated as finished work. Nobody was reviewing it for architectural decisions, only for whether it ran. Code that runs is not the same as code that is correct, maintainable, or operable by someone other than the person who generated it.
Airflow is not a hard tool to use correctly. The documentation is explicit about what operators should and should not do. The mistake wasn’t using AI to write the code. The mistake was skipping the step where an experienced engineer decides whether what was generated actually reflects how the tool is supposed to work.
A system that only one person can operate is not a system. It’s a dependency.
Rescue helps teams identify and replace fragile pipeline architecture before it becomes a business problem. If your data platform has a “works on my machine” quality to it, let’s talk.