Some problems look like data engineering problems. This one turned out to be a vendor management problem wearing a data engineering costume.
Context
A client in the online gaming space ran paid marketing campaigns across 16 different vendors: display, affiliate, search, social. Each vendor had their own reporting format. Some sent Excel files. Some sent PDFs. Some sent screenshots of dashboards. A few sent all three, inconsistently, depending on who was at the account that week.
The previous team had solved this with an AI layer: a pipeline that ingested whatever the vendor sent, ran it through a model to extract the relevant fields, and pushed the output downstream. On paper, elegant. In practice, a slow-motion disaster.
The problem
The AI worked. Sometimes. The issue was that “sometimes” is not a property you want in a data pipeline.
Vendor A sends a PDF → AI extracts cost: $48,200 ✓
Vendor A sends the same PDF next week → AI extracts cost: $48.2 ✗
No malfunction. No error thrown. No alert fired. The model just interpreted things differently on different runs. Reach figures hallucinated. Campaign IDs got dropped when the formatting shifted slightly. Costs came back in the wrong currency because the model inferred the locale from context that wasn’t always there.
The client had been running dashboards on top of this for months without knowing how much of the data was wrong. When we ran a manual audit against vendor invoices, the gap was significant. Nobody had noticed because the numbers looked plausible.
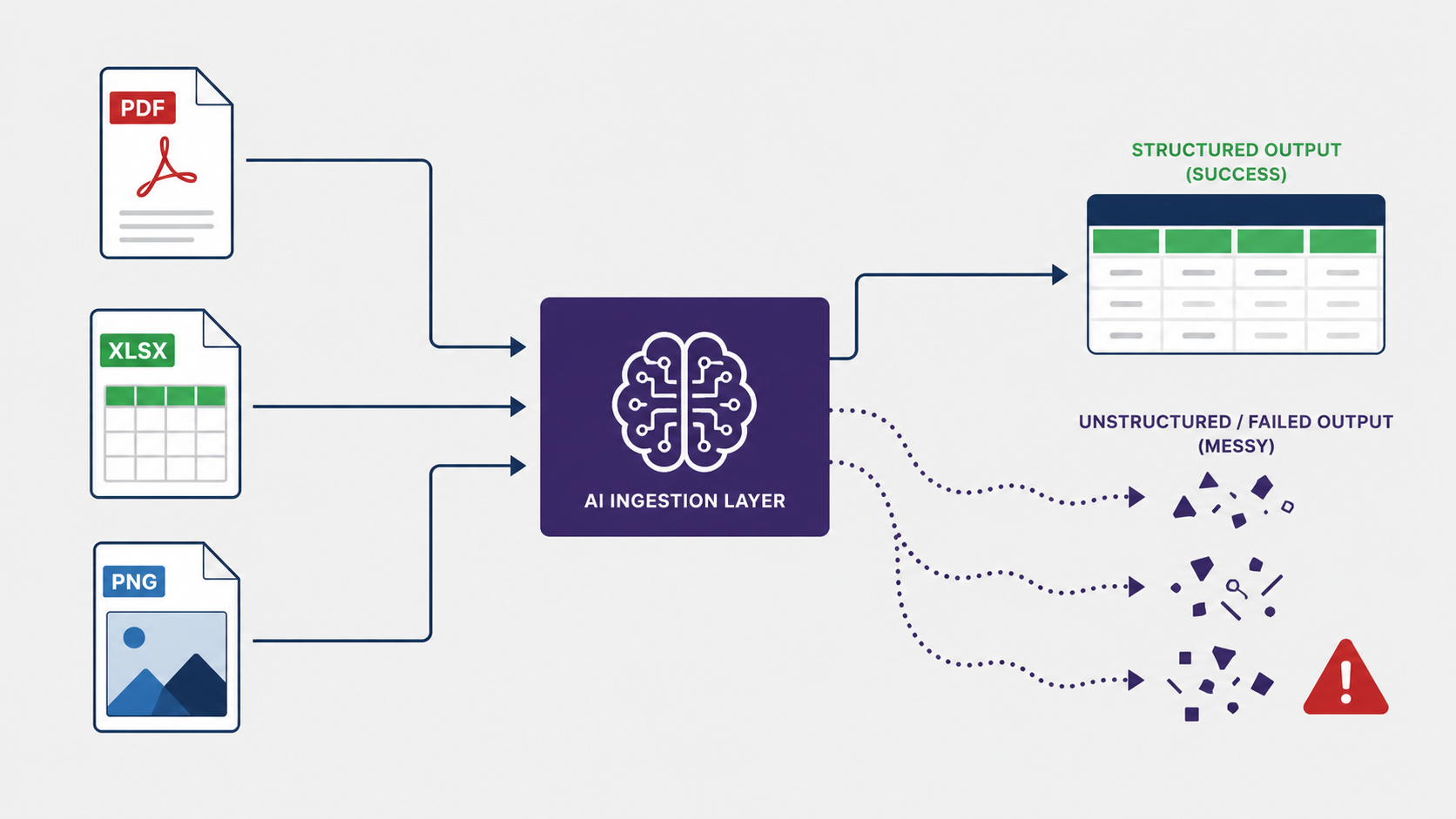
This is the core issue with using generative models for structured data extraction: the output space is unbounded. A dbt transformation either runs or it doesn’t. An AI extraction layer can succeed, partially succeed, or confidently produce wrong answers, and all three cases look identical downstream. There is no failed run to alert on. The data just lands wrong.
When we found this, we didn’t patch the AI layer. We removed it entirely and wrote off the cost. The bad historical data was harder to deal with: we had no clean source of truth to backfill from, so we flagged everything before a cutoff date as unreliable in the reporting layer and moved forward from there. Not ideal, but honest.
The fix
The principle was simple: instead of adapting our ingestion to whatever vendors decided to send, we defined what vendors were required to send. Data quality enforcement moved from our pipeline to the source.
We built a format specification for each marketing channel. The requirements were intentionally minimal:
| Required columns | Notes |
|---|---|
date | YYYY-MM-DD, one row per day |
campaign_id | Vendor’s own identifier, stable across reports |
channel | e.g. display, search, affiliate |
reach | Integer, no formatting |
cost_usd | Decimal, USD, no currency symbols |
Beyond that, vendors could include as many additional columns as they wanted. Impression breakdowns, click-through rates, custom attribution models, all welcome. The schema was open on the right side intentionally: vendors want to demonstrate the value of their work, so giving them room to bring their own metrics created natural buy-in for a spec that was otherwise non-negotiable.
# Validation suite (Great Expectations, simplified)
expect_column_to_exist("date")
expect_column_values_to_match_regex("date", r"^\d{4}-\d{2}-\d{2}$")
expect_column_values_to_not_be_null("campaign_id")
expect_column_values_to_be_of_type("cost_usd", "float")
expect_column_values_to_be_between("cost_usd", min_value=0)
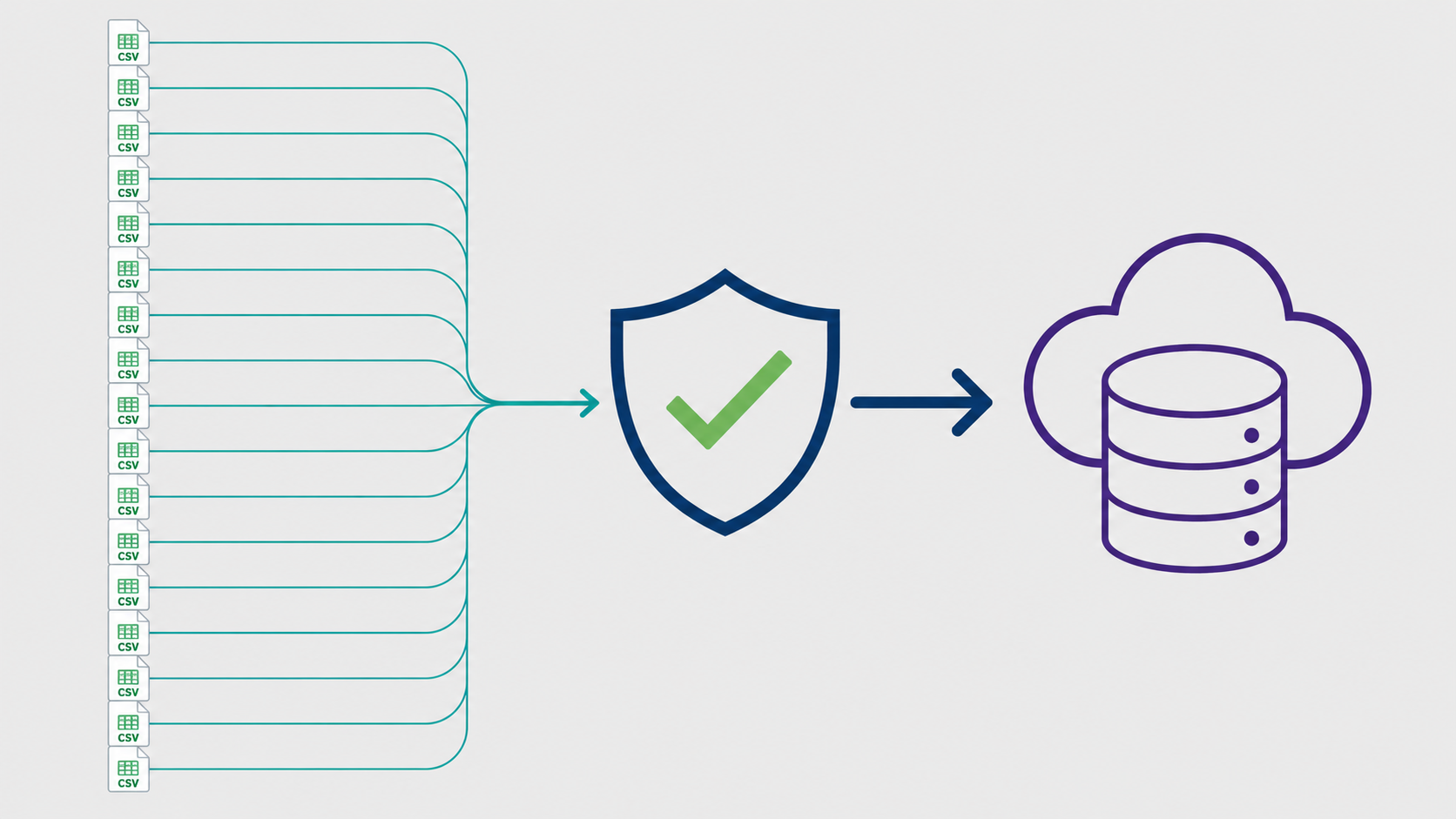
Submissions came through a lightweight internal portal: a simple upload interface that ran the validation suite on ingest and returned an immediate pass/fail with a human-readable error report. If the file didn’t pass, the vendor saw exactly which rows and columns failed and why. No emails, no back-and-forth, no “can you check this file we sent last Tuesday.”
On the pipeline side, the load job became trivial. Files in GCS with a valid schema flag get picked up by a Composer DAG, loaded raw into a BigQuery staging table, and promoted to production after a row-count check. No transformation handles format ambiguity because there is no ambiguity left by the time the file lands.
The hard part
We had the validation layer working in week two. The remaining eleven weeks of a three-month engagement were spent on vendor onboarding.
This is the part that does not show up in architecture diagrams. Some vendors pushed back hard. A few had internal reporting tools that could not export in the required format without custom development on their end. One sent a 40-slide deck explaining why their proprietary format was superior. We held the line. The client was the one signing their invoices, and we made sure everyone understood that.
The pattern that emerged was revealing: the vendors who cooperated fastest had clean internal data. The ones who struggled longest had messy internal reporting, which meant they could not easily produce a consistent extract. That alone was useful intelligence for the client, who had no visibility into how organized their vendors actually were.
By month three, all 16 vendors were submitting clean, validated CSVs. The pipeline ran daily without surprises. The client could trust their dashboards for the first time.
What this cost
Three months of work, the majority of it on vendor communication rather than engineering. The technical implementation was maybe three weeks total. The rest was emails, calls, and the occasional escalation through the client’s account management team.
The AI ingestion layer had been sold as a “future-proof” solution: flexible enough to handle any format, ever. What it actually delivered was opacity. Every metric in every dashboard was downstream of a black box that occasionally made things up, silently, with no way to tell when it had.
The replacement was less impressive to demo. A CSV template is not a compelling slide. But it ran every day, the data matched the invoices, and nobody had to wonder whether this week’s numbers were real.
Rescue helps teams identify and replace fragile pipeline architecture before it becomes a business problem. If your ingestion layer has a “sometimes it works” quality to it, let’s talk.